In this somewhat different post, I am hosting the long-running Carnival of Mathematics. First I’ll talk about 223 (the issue number) and then I’ll round up some mathematical posts from December 2023.
It’s primetime we talk about 223. First of all, it is a lucky prime, to which it is unknown if there are infinitely many. To write the number 223 as the sum of fifth powers requires 37 terms, more than any other number. This is an example of Waring’s problem has a rich history going back to Diophantus nearly 2000 years ago. Also, 223 is the number of permutations on 6 elements that have a strong fixed point (see below for Python code).
And now for what happened last month.
- Quanta brings current research mathematics to a general audience. Solutions to long-standing problems happen all the time in math, and this video highlights some from the past year. The one I know the most about is at the end. The “Dense Sets have 3-term Arithmetic Progressions” problem has been the subject of intense study for over 70 years. Multiple Fields medal winners over several generations have studied the problem and a big breakthrough was made by two computer scientists (including a PhD student from my Alma mater).
- Quanta also posted their Year in Math. Particularly interesting to me is Andrew Granville’s (my former Mentor) discussion of the intersection of computation and mathematics.
- Here you can find a “Theorem of the Day,” where the author impressively keeps posting interesting theorems from mathematics on a daily basis.
- An interesting story of a Math SAT problem with no correct answer.
- John Cook’s explanation of a Calculus trick. See if you can figure out how his trick is a manifestation of the fact that for a right triangle with angle
,
only depends on the ration of the non-hypotenuse sides.
- If you are interested in some drawings with math and a little bit of humor, you can find that here.
- Another article from Quanta highlighting a very recent breakthrough. Interesting to me is how quickly (3 weeks!) the result was formalized into computers. What this means is a group of people got together and input all of the results into a computer which then tested the validity of the results in an automated way. This process of inputting the results into the computer can be quite painful and I am impressed by the speed at which it was done. You can check out my previous blog post for my experience with it. Incidentally, one of the classical results I helped formalized in that blog post was used to formalize the recent result. The referee and review process for math papers is particularly painful for mathematicians. It is not uncommon to see mathematicians submit a paper and wait years for the decision to accept or reject to come in. Meanwhile, especially for younger mathematicians, their career hangs in the balance as they await these decisions. Adopting Software Engineering best practices to this process, as done above, I believe go a long way to alleviate some of this anguish.
Here is the Python code for the strong fixed point verification.
from itertools import permutations
perms = permutations([1,2,3,4,5,6])
def fixed_points(perm):
"""
Input: a permutation written as a tuple, i.e. (1,3,2) for 1->1, 2->3, 3->2
Output: a list of the indices of the fixed point of the permutation
"""
return [ind for ind,p_ind in enumerate(perm) if ind+1 == p_ind]
def is_strong_fixed_point(ind,perm):
"""
Input: An index and a permutation
Output: True if the index is a strong fixed point of the permutation, else False
See here: https://oeis.org/A006932
"""
for lesser_ind in range(0,ind):
if perm[lesser_ind] > perm[ind]:
return False
for greater_ind in range(ind+1,len(perm)):
if perm[greater_ind] < perm[ind]:
return False
return True
counter = 0
for perm in perms:
for fixed_point in fixed_points(perm):
if is_strong_fixed_point(fixed_point,perm):
counter +=1
break
print(counter)

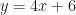 passes through
passes through  . What is the
. What is the 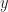 -coordinate of the point where this line crosses the
-coordinate of the point where this line crosses the 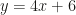 has the same slope, the desired line has slope 4. Therefore, the equation of the line is of the form
has the same slope, the desired line has slope 4. Therefore, the equation of the line is of the form 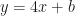 . Plugging in the point
. Plugging in the point  , so
, so 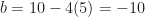 . Therefore, the
. Therefore, the  .
. . Setting
. Setting 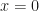 , we find
, we find  .
.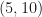 , then it is of the form
, then it is of the form  . Expanding the right side gives
. Expanding the right side gives 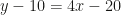 , so
, so 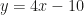 . Setting
. Setting  , we find that the line crosses the
, we find that the line crosses the 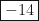 .
.
 close to 0), the model outputs the first character nearly all the time. But as the temperature grows larger, the model outputs each character around half the time.
close to 0), the model outputs the first character nearly all the time. But as the temperature grows larger, the model outputs each character around half the time. 
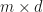 matrix
matrix 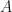 can be written as
can be written as 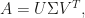
 is
is  for
for  .
. 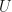 and
and  are
are 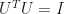 and
and 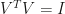 .
. 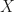 , that is a matrix where each of the
, that is a matrix where each of the 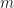 rows are data points with
rows are data points with 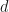 features.
features. 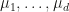 , respectively. For instance if
, respectively. For instance if ![X = \left[\begin{matrix}1 & 2\\3 & 4\\5 & 6\end{matrix}\right] ,](https://s0.wp.com/latex.php?latex=X+%3D+%5Cleft%5B%5Cbegin%7Bmatrix%7D1+%26+2%5C%5C3+%26+4%5C%5C5+%26+6%5Cend%7Bmatrix%7D%5Cright%5D+%2C&bg=ffffff&fg=141412&s=0&c=20201002)
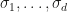 . Thus in our example we divide the first column and second column by
. Thus in our example we divide the first column and second column by 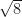 . Let us call this new scaled matrix
. Let us call this new scaled matrix 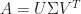
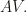
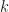 components, the data point in the
components, the data point in the 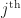 row of
row of 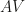 .
.  , we compute PCA in two steps:
, we compute PCA in two steps: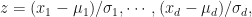

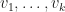 are the first
are the first  align with our computations above.
align with our computations above. 




 , where
, where 

 , instead of the original
, instead of the original  . Also, through scaling, the data now lies near the line
. Also, through scaling, the data now lies near the line  , rather than
, rather than  .
. 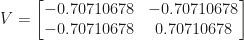
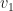 is a scalar multiple times
is a scalar multiple times
 is a scalar multiple of
is a scalar multiple of 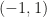 .
. , up to a small error. PCA is a way of automating the process of finding this
, up to a small error. PCA is a way of automating the process of finding this 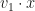 , for a data point
, for a data point 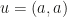 we have
we have 
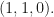



 comes from, leading us to some classical Probability Theory. We will first talk about the math with some examples and then quickly make the connection.
comes from, leading us to some classical Probability Theory. We will first talk about the math with some examples and then quickly make the connection.  be a $d$-
be a $d$-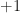 or
or 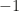 Then we may write
Then we may write 

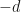 . However, what we would like to know the average behavior of this sum
. However, what we would like to know the average behavior of this sum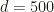 and compute the sum of 100,000 random vectors each with
and compute the sum of 100,000 random vectors each with  entries.
entries. 
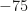 or larger than 75.
or larger than 75.  . Here
. Here 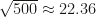 , and it is a general phenomenon that most of the sums will lie between, say,
, and it is a general phenomenon that most of the sums will lie between, say, 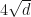 and
and 
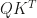 is the dot product a row of
is the dot product a row of  and a row of
and a row of 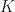 :
:
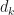 numbers, and by the square root cancellation principle, we expect the sum to be of order
numbers, and by the square root cancellation principle, we expect the sum to be of order 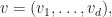



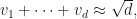
 precisely. Thus if we have a sum of
precisely. Thus if we have a sum of 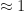 .
. ![E[ \left( v_1^2 + \cdots + v_d^2 \right) ] = \sum_{j} E[v_j^2]](https://s0.wp.com/latex.php?latex=E%5B+%5Cleft%28+v_1%5E2+%2B+%5Ccdots+%2B+v_d%5E2+%5Cright%29+%5D+%3D+%5Csum_%7Bj%7D+E%5Bv_j%5E2%5D&bg=ffffff&fg=141412&s=0&c=20201002)
![E[ \left( v_1^2 + \cdots + v_d^2 \right) ]= E[\sum_{ i,j} v_i v_j ] =\sum_{ i,j} E[v_i v_j ] ,](https://s0.wp.com/latex.php?latex=E%5B+%5Cleft%28+v_1%5E2+%2B+%5Ccdots+%2B+v_d%5E2+%5Cright%29+%5D%3D+E%5B%5Csum_%7B+i%2Cj%7D+v_i+v_j+%5D+%3D%5Csum_%7B+i%2Cj%7D+E%5Bv_i+v_j+%5D+%2C&bg=ffffff&fg=141412&s=0&c=20201002)
![\sum_{ i,j} E[v_i v_j ] = 0,](https://s0.wp.com/latex.php?latex=%5Csum_%7B+i%2Cj%7D+E%5Bv_i+v_j+%5D++%3D+0%2C&bg=ffffff&fg=141412&s=0&c=20201002)

 possibilities, all of ASCII can be represented by 1 byte (with room to spare). UTF-8 is an attempt to convert the Unicode code points to bytes in an efficient manner.
possibilities, all of ASCII can be represented by 1 byte (with room to spare). UTF-8 is an attempt to convert the Unicode code points to bytes in an efficient manner. 







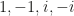 is
is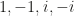 is
is 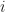 . The inverse of an element
. The inverse of an element  is the identity element of the group. In this group,
is the identity element of the group. In this group, 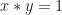 .
.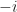 , because
, because 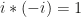 . Similarly, the inverse of
. Similarly, the inverse of 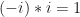 .
. into
into 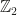 . They are defined as follows:
. They are defined as follows: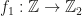 such that
such that  for all
for all 
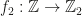 such that
such that  for all
for all 
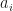 is the number of permutations in S_5 with i cycles, and
is the number of permutations in S_5 with i cycles, and 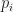 is a variable representing a cycle of length i.
is a variable representing a cycle of length i.

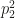 in this expression is
in this expression is  , so the number of permutations in S_5 with cycle type [2,2] is
, so the number of permutations in S_5 with cycle type [2,2] is  .
. is not even an integer, which is certainly not right. Indeed, the index of a subgroup counts something and most be a positive integer.
is not even an integer, which is certainly not right. Indeed, the index of a subgroup counts something and most be a positive integer.  is 5, using our algebra skills. Then we can prompt chat-GPT with the following.
is 5, using our algebra skills. Then we can prompt chat-GPT with the following.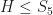 is a subgroup of order 5. What is the index of
is a subgroup of order 5. What is the index of  in
in  ?
?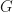 is the number of left cosets of
is the number of left cosets of 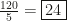 .
.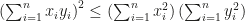
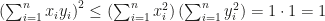

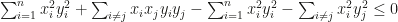

![\sum_{i \ne j} (x_i y_i)(x_j y_j) - \sum_{i \ne j} [(x_i y_j)^2]^{\frac{1}{2}}[(x_i y_j)^2]^{\frac{1}{2}} \le 0](https://s0.wp.com/latex.php?latex=%5Csum_%7Bi+%5Cne+j%7D+%28x_i+y_i%29%28x_j+y_j%29+-+%5Csum_%7Bi+%5Cne+j%7D+%5B%28x_i+y_j%29%5E2%5D%5E%7B%5Cfrac%7B1%7D%7B2%7D%7D%5B%28x_i+y_j%29%5E2%5D%5E%7B%5Cfrac%7B1%7D%7B2%7D%7D+%5Cle+0&bg=ffffff&fg=141412&s=0&c=20201002)
![\sum_{i \ne j} (x_i y_i)(x_j y_j) - \left(\sum_{i \ne j} [(x_i y_j)^2]^{\frac{1}{2}}\right)^2 \le 0](https://s0.wp.com/latex.php?latex=%5Csum_%7Bi+%5Cne+j%7D+%28x_i+y_i%29%28x_j+y_j%29+-+%5Cleft%28%5Csum_%7Bi+%5Cne+j%7D+%5B%28x_i+y_j%29%5E2%5D%5E%7B%5Cfrac%7B1%7D%7B2%7D%7D%5Cright%29%5E2+%5Cle+0&bg=ffffff&fg=141412&s=0&c=20201002)
![\sum_{i \ne j} (x_i y_i)(x_j y_j) - \left[\prod_{i \ne j} [(x_i y_j)^2]^{\frac{1}{2}}\right]^{\frac{2}{n-1}} \le 0](https://s0.wp.com/latex.php?latex=%5Csum_%7Bi+%5Cne+j%7D+%28x_i+y_i%29%28x_j+y_j%29+-+%5Cleft%5B%5Cprod_%7Bi+%5Cne+j%7D+%5B%28x_i+y_j%29%5E2%5D%5E%7B%5Cfrac%7B1%7D%7B2%7D%7D%5Cright%5D%5E%7B%5Cfrac%7B2%7D%7Bn-1%7D%7D+%5Cle+0&bg=ffffff&fg=141412&s=0&c=20201002)
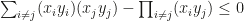

 be finite sets. Then
be finite sets. Then